【我們為什麼挑選這篇文章】我是一個毫無程式基礎的文組生,一直都對機器學習很有興趣卻不知道怎麼入門。
前幾天真的是意外在中國網站上發現這篇文章,進而開始聽 Tom Mitchell 的線上課程,結果很意外的我居然就停不下來的一直聽下去,他的英語發音清晰,表達又簡單明瞭,讓我非常喜歡!很期待慢慢發掘這篇文章中的學習資源,也很推薦給大家!(責任編輯:劉庭瑋)
分享一篇來自機器之心的文章。關於機器學習的起步,講的還是很清楚的。
Python 可以說是現在最流行的機器學習語言,而且你也能在網上找到大量的資源。你現在也在考慮從 Python 入門機器學習嗎?本教程或許能幫你成功上手,從 0 到 1 掌握 Python 機器學習,至於後面再從 1 到 100 變成機器學習專家,就要看你自己的努力了。本教程原文分為兩個部分,機器之心在本文中將其進行了整合,原文可參閱:suo.im/KUWgl 和 suo.im/96wD3。本教程的作者為 KDnuggets 副主編兼數據科學家 Matthew Mayo。
「開始」往往是最難的,尤其是當選擇太多的時候,一個人往往很難下定決定做出選擇。本教程的目的是幫助幾乎沒有 Python 機器學習背景的新手成長為知識淵博的實踐者,而且這個過程中僅需要使用免費的材料和資源即可 。這個大綱的主要目標是帶你了解那些數量繁多的可用資源。毫無疑問,資源確實有很多,但哪些才是最好的呢?哪些是互補的呢?以怎樣的順序學習這些資源才是最合適的呢?
首先,我假設你並不是以下方面的專家:
- 機器學習
- Python
- 任何 Python 的機器學習、科學計算或數據分析庫
當然,如果你對前兩個主題有一定程度的基本了解就更好了,但那並不是必要的,在早期階段多花一點點時間了解一下就行了。
基礎篇
第一步:基本 Python 技能
如果我們打算利用 Python 來執行機器學習,那麼對 Python 有一些基本的了解就是至關重要的。幸運的是,因為 Python 是一種得到了廣泛使用的通用編程語言,加上其在科學計算和機器學習領域的應用,所以找到一個初學者教程並不十分困難。你在 Python 和編程上的經驗水平對於起步而言是至關重要的。
首先,你需要安裝 Python。因為我們後面會用到科學計算和機器學習軟件包,所以我建議你安裝 Anaconda。這是一個可用於 Linux、OS X 和 Windows 上的工業級的 Python 實現,完整包含了機器學習所需的軟件包,包括 numpy、scikit-learn 和 matplotlib。其也包含了 iPython Notebook,這是一個用在我們許多教程中的交互式環境。我推薦安裝 Python 2.7。
如果你不懂編程,我建議你從下面的免費在線書籍開始學習,然後再進入後續的材料:
- Learn Python the Hard Way,作者 Zed A. Shaw:https:// learnpythonthehardway.org /book/
如果你有編程經驗,但不懂 Python 或還很初級,我建議你學習下面兩個課程:
- 谷歌開發者 Python 課程(強烈推薦視覺學習者學習):http:// suo.im/toMzq
- Python 科學計算入門(來自 UCSB Engineering 的 M. Scott Shell)(一個不錯的入門,大約有 60 頁):http:// suo.im/2cXycM
如果你要 30 分鐘上手 Python 的快速課程,看下面:
當然,如果你已經是一位經驗豐富的 Python 程序員了,這一步就可以跳過了。即便如此,我也建議你常使用 Python 文檔:https://www. python.org/doc/
第二步:機器學習基礎技巧
KDnuggets 的 Zachary Lipton 已經指出:現在,人們評價一個「數據科學家」已經有很多不同標準了。這實際上是機器學習領域領域的一個寫照,因為數據科學家大部分時間幹的事情都牽涉到不同程度地使用機器學習算法。為了有效地創造和獲得來自支持向量機的洞見,非常熟悉核方法(kernel methods)是否必要呢?當然不是。就像幾乎生活中的所有事情一樣,掌握理論的深度是與實踐應用相關的。對機器學習算法的深度了解超過了本文探討的範圍,它通常需要你將非常大量的時間投入到更加學術的課程中去,或者至少是你自己要進行高強度的自學訓練。
好消息是,對實踐來說,你並不需要獲得機器學習博士般的理論理解——就想要成為一個高效的程序員並不必要進行計算機科學理論的學習。
人們對 吳恩達在 Coursera 上的機器學習課程 內容往往好評如潮; 然而,我的建議是瀏覽前一個學生在線記錄的課堂筆記。 跳過特定於 Octave(一個類似於 Matlab 的與你 Python 學習無關的語言)的筆記。一定要明白這些都不是官方筆記,但是可以從它們中把握到吳恩達課程材料中相關的內容。當然如果你有時間和興趣,你現在就可以去 Coursera 上學習吳恩達的機器學習課程:http:// suo.im/2o1uD
- 吳恩達課程的非官方筆記:http://www. holehouse.org/mlclass/
除了上面提到的吳恩達課程,如果你還需要需要其它的,網上還有很多各類課程供你選擇。比如 我就很喜歡 Tom Mitchell,這裡是他最近演講的視頻(一起的還有 Maria-Florina Balcan),非常平易近人 。
- Tom Mitchell 的機器學習課程:http:// suo.im/497arw
目前你不需要所有的筆記和視頻。一個有效地方法是當你覺得合適時,直接去看下面特定的練習題,參考上述備註和視頻恰當的部分,
第三步:科學計算 Python 軟件包概述
好了,我們已經掌握了 Python 編程並對機器學習有了一定的了解。而在 Python 之外,還有一些常用於執行實際機器學習的開源軟件庫。廣義上講,有很多所謂的科學 Python 庫(scientific Python libraries)可用於執行基本的機器學習任務(這方面的判斷肯定有些主觀性):
- numpy——主要對其 N 維數組對像有用 http://www. numpy.org/
- pandas——Python 數據分析庫,包括數據框架(dataframes)等結構 http:// pandas.pydata.org/
- matplotlib——一個 2D 繪圖庫,可產生出版物質量的圖表 http:// matplotlib.org/
- scikit-learn——用於數據分析和數據挖掘人物的機器學習算法 http:// scikit-learn.org/stable /
學習這些庫的一個好方法是學習下面的材料:
- Scipy Lecture Notes,來自 Gaël Varoquaux、Emmanuelle Gouillart 和 Olav Vahtras:http://www. scipy-lectures.org/
- 這個 pandas 教程也很不錯:10 Minutes to Pandas:http:// suo.im/4an6gY
在本教程的後面你還會看到一些其它的軟件包,比如基於 matplotlib 的數據可視化庫 Seaborn。前面提到的軟件包只是 Python 機器學習中常用的一些核心庫的一部分,但是理解它們應該能讓你在後面遇到其它軟件包時不至於感到困惑。
下面就開始動手吧!
第四步:使用 Python 學習機器學習
首先檢查一下準備情況
- Python:就緒
- 機器學習基本材料:就緒
- Numpy:就緒
- Pandas:就緒
- Matplotlib:就緒
現在是時候使用 Python 機器學習標準庫 scikit-learn 來實現機器學習算法了。
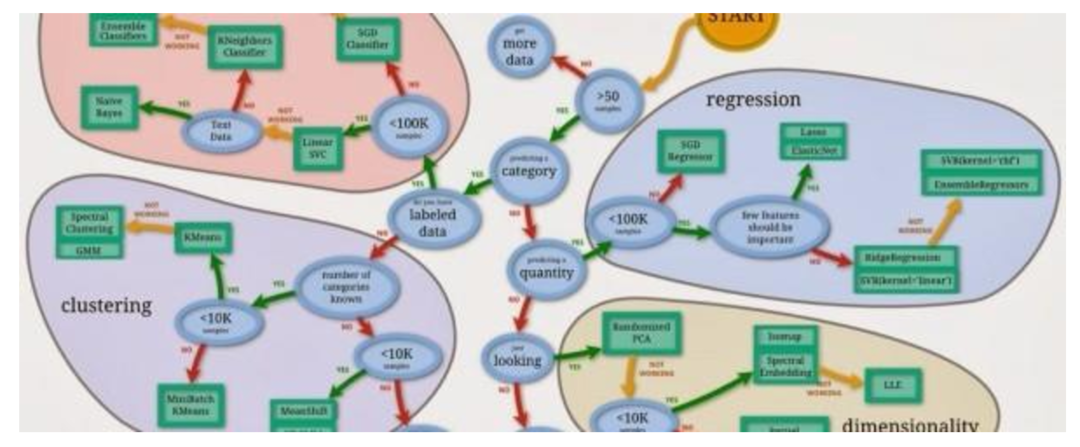 scikit-learn 流程圖
scikit-learn 流程圖
下面許多的教程和訓練都是使用 iPython (Jupyter) Notebook 完成的, iPython Notebook 是執行 Python 語句的交互式環境。iPython Notebook 可以很方便地在網上找到或下載到你的本地計算機。
- 來自史丹佛的 iPython Notebook 概覽:http:// cs231n.github.io/ipytho n-tutorial/
同樣也請注意,以下的教程是由一系列在線資源所組成。如果你感覺課程有什麼不合適的,可以和作者交流。我們第一個教程就是從 scikit-learn 開始的,我建議你們在繼續完成教程前可以按順序看一看以下的文章。
下面是一篇是對 scikit-learn 簡介的文章,scikit-learn 是 Python 最常用的通用機器學習庫,其覆蓋了 K 近鄰算法:
- Jake VanderPlas 寫的 scikit-learn 簡介:http:// suo.im/3bMdEd
下面的會更加深入、擴展的一篇簡介,包括了從著名的數據庫開始完成一個項目:
- Randal Olson 的機器學習案例筆記:http:// suo.im/RcPR6
下一篇關注於在 scikit-learn 上評估不同模型的策略,包括訓練集/測試集的分割方法:
- Kevin Markham 的模型評估:http:// suo.im/2HIXDD
第五步:Python 上實現機器學習的基本算法
在有了 scikit-learn 的基本知識後,我們可以進一步探索那些更加通用和實用的算法。我們從非常出名的 K 均值聚類(k-means clustering)算法開始,它是一種非常簡單和高效的方法,能很好地解決非監督學習問題:
- K-均值聚類:http:// suo.im/40R8zf
接下來我們可以回到分類問題,並學習曾經最流行的分類算法:
在了解分類問題後,我們可以繼續看看連續型數值預測:
我們也可以利用回歸的思想應用到分類問題中,即 logistic 回歸:
- logistic 回歸:http:// suo.im/S2beL
第六步:Python 上實現進階機器學習算法
我們已經熟悉了 scikit-learn,現在我們可以了解一下更高級的算法了。首先就是支持向量機,它是一種依賴於將數據轉換映射到高維空間的非線性分類器。
- 支持向量機:http:// suo.im/2iZLLa
隨後,我們可以通過 Kaggle Titanic 競賽檢查學習作為集成分類器的隨機森林:
- Kaggle Titanic 競賽(使用隨機森林):http:// suo.im/1o7ofe
降維算法經常用於減少在問題中所使用的變量。主成份分析法就是非監督降維算法的一個特殊形式:
在進入第七步之前,我們可以花一點時間考慮在相對較短的時間內取得的一些進展。
首先使用 Python 及其機器學習庫,我們不僅已經了解了一些最常見和知名的機器學習算法(k 近鄰、k 均值聚類、支持向量機等),還研究了強大的集成技術(隨機森林)和一些額外的機器學習任務(降維算法和模型驗證技術)。除了一些基本的機器學習技巧,我們已經開始尋找一些有用的工具包。
我們會進一步學習新的必要工具。
第七步:Python 深度學習
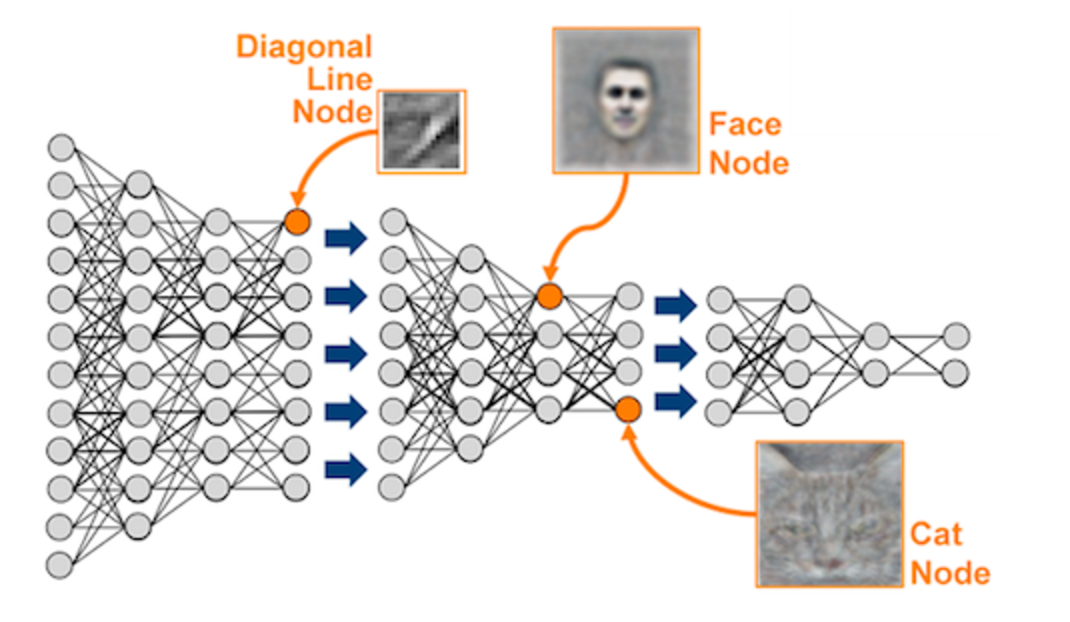
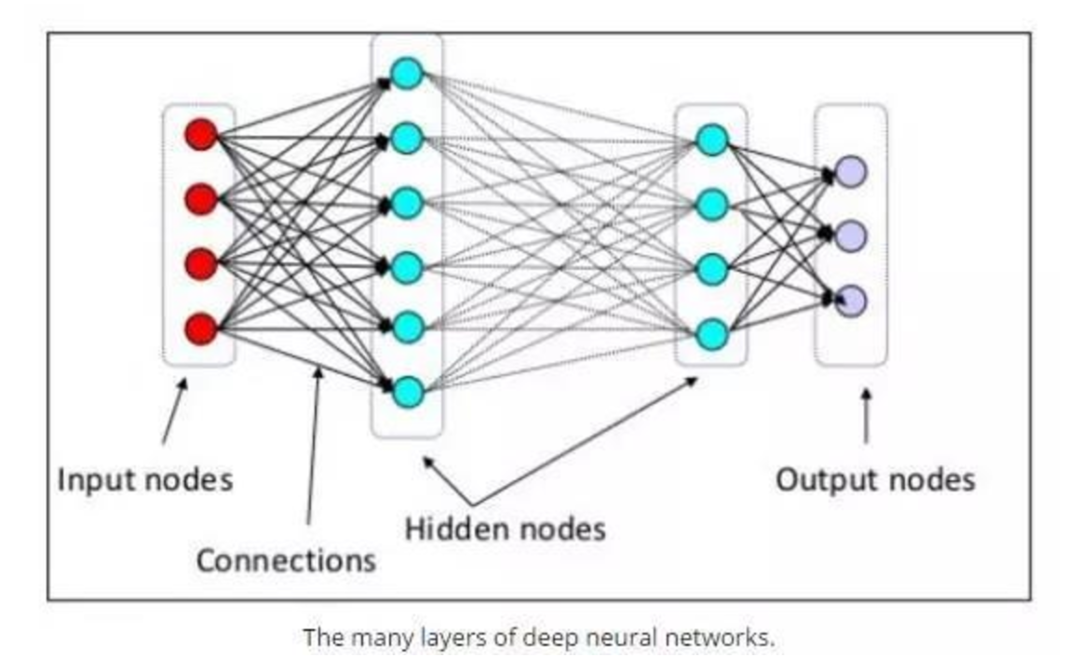
神經網絡包含很多層
深度學習無處不在。深度學習建立在幾十年前的神經網絡的基礎上,但是最近的進步始於幾年前,並極大地提高了深度神經網絡的認知能力,引起了人們的廣泛興趣。如果你對神經網絡還不熟悉,KDnuggets 有很多文章詳細介紹了最近深度學習大量的創新、成就和讚許。
最後一步並不打算把所有類型的深度學習評論一遍,而是在 2 個先進的當代 Python 深度學習庫中探究幾個簡單的網絡實現。對於有興趣深挖深度學習的讀者,我建議從下面這些免費的在線書籍開始:
- 神經網絡與深度學習,作者 Michael Nielsen:http:// neuralnetworksanddeeplearning.com /
-
Theano
鏈接:http:// deeplearning.net/softwa re/theano/
Theano 是我們講到的第一個 Python 深度學習庫。看看 Theano 作者怎麼說:
Theano 是一個 Python 庫,它可以使你有效地定義、優化和評估包含多維數組的數學表達式。
下面關於運用 Theano 學習深度學習的入門教程有點長,但是足夠好,描述生動,評價很高:
- Theano 深度學習教程,作者 Colin Raffel:http:// suo.im/1mPGHe
2. Caffe
鏈接:http:// caffe.berkeleyvision.org /
另一個我們將測試驅動的庫是 Caffe。再一次,讓我們從作者開始:
Caffe 是一個深度學習框架,由表達、速度和模塊性建構,Bwekeley 視覺與學習中心和社區工作者共同開發了 Caffe。
這個教程是本篇文章中最好的一個。我們已經學習了上面幾個有趣的樣例,但沒有一個可與下面這個樣例相競爭,其可通過 Caffe 實現谷歌的 DeepDream。這個相當精彩!掌握教程之後,可以嘗試使你的處理器自如運行,就當作是娛樂。
通過 Caffe 實現谷歌 DeepDream:http:// suo.im/2cUSXS
我並沒有保證說這會很快或容易,但是如果你投入了時間並完成了上面的 7 個步驟,你將在理解大量機器學習算法以及通過流行的庫(包括一些在目前深度學習研究領域最前沿的庫)在 Python 中實現算法方面變得很擅長。
進階篇
機器學習算法
本篇是使用 Python 掌握機器學習的 7 個步驟系列文章的下篇,如果你已經學習了該系列的上篇,那麼應該達到了令人滿意的學習速度和熟練技能;如果沒有的話,你也許應該回顧一下上篇,具體花費多少時間,取決於你當前的理解水平。我保證這樣做是值得的。快速回顧之後,本篇文章會更明確地集中於幾個機器學習相關的任務集上。由於安全地跳過了一些基礎模塊——Python 基礎、機器學習基礎等等——我們可以直接進入到不同的機器學習算法之中。這次我們可以根據功能更好地分類教程。
第 1 步:機器學習基礎回顧& 一個新視角
上篇中包括以下幾步:
1. Python 基礎技能
2. 機器學習基礎技能
3. Python 包概述
4. 運用 Python 開始機器學習:介紹& 模型評估
5. 關於 Python 的機器學習主題:k-均值聚類、決策樹、線性回歸& 邏輯回歸
6. 關於 Python 的高階機器學習主題:支持向量機、隨機森林、PCA 降維 7. Python 中的深度學習
如上所述,如果你正準備從頭開始,我建議你按順序讀完上篇。我也會列出所有適合新手的入門材料,安裝說明包含在上篇文章中。
然而,如果你已經讀過,我會從下面最基礎的開始:
- 機器學習關鍵術語解釋,作者 Matthew Mayo。地址:http:// suo.im/2URQGm
- 維基百科條目:統計學分類。地址:http:// suo.im/mquen
- 機器學習:一個完整而詳細的概述,作者 Alex Castrounis。地址:http:// suo.im/1yjSSq
如果你正在尋找學習機器學習基礎的替代或補充性方法,恰好我可以把正在看的 Shai Ben-David 的視頻講座和 Shai Shalev-Shwartz 的教科書推薦給你:
- Shai Ben-David 的機器學習介紹視頻講座,滑鐵盧大學。地址:http:// suo.im/1TFlK6
- 理解機器學習:從理論到算法,作者 Shai Ben-David & Shai Shalev-Shwartz。地址:http:// suo.im/1NL0ix
記住,這些介紹性資料並不需要全部看完才能開始我寫的系列文章。視頻講座、教科書及其他資源可在以下情況查閱:當使用機器學習算法實現模型時或者當合適的概念被實際應用在後續步驟之中時。具體情況自己判斷。
第 2 步:更多的分類
我們從新材料開始,首先鞏固一下我們的分類技術並引入一些額外的算法。雖然本篇文章的第一部分涵蓋決策樹、支持向量機、邏輯回歸以及合成分類隨機森林,我們還是會添加 k-最近鄰、樸素貝葉斯分類器和多層感知器。
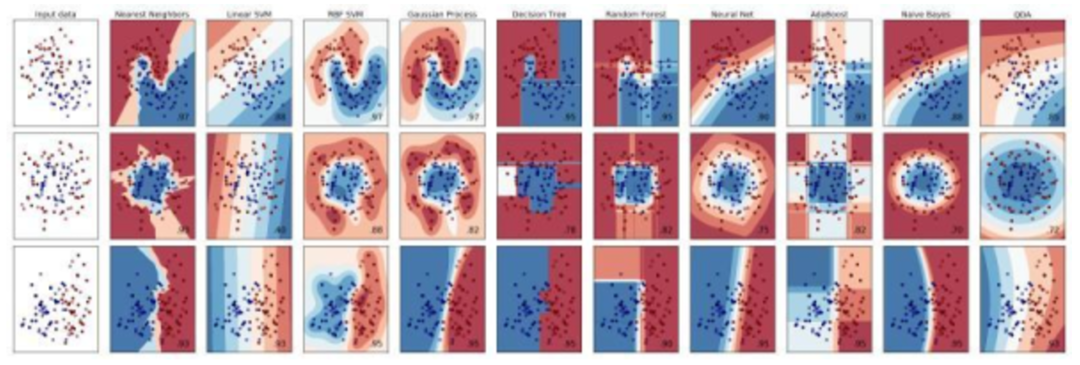
Scikit-learn 分類器
k-最近鄰(kNN)是一個簡單分類器和懶惰學習者的示例,其中所有計算都發生在分類時間上(而不是提前在訓練步驟期間發生)。kNN 是非參數的,通過比較數據實例和 k 最近實例來決定如何分類。
- 使用 Python 進行 k-最近鄰分類。地址:http:// suo.im/2zqW0t
樸素貝葉斯是基於貝葉斯定理的分類器。它假定特徵之間存在獨立性,並且一個類中任何特定特徵的存在與任何其它特徵在同一類中的存在無關。
- 使用 Scikit-learn 進行文檔分類,作者 Zac Stewart。地址:http:// suo.im/2uwBm3
多層感知器(MLP)是一個簡單的前饋神經網絡,由多層節點組成,其中每個層與隨後的層完全連接。多層感知器在 Scikit-learn 版本 0.18 中作了介紹。
首先從 Scikit-learn 文檔中閱讀 MLP 分類器的概述,然後使用教程練習實現。
- 神經網絡模型(監督式),Scikit-learn 文檔。地址:http:// suo.im/3oR76l
- Python 和 Scikit-learn 的神經網絡初學者指南 0.18!作者 Jose Portilla。地址:http:// suo.im/2tX6rG
第 3 步:更多聚類
我們現在接著講聚類,一種無監督學習形式。上篇中,我們討論了 k-means 算法; 我們在此介紹 DBSCAN 和期望最大化(EM)。
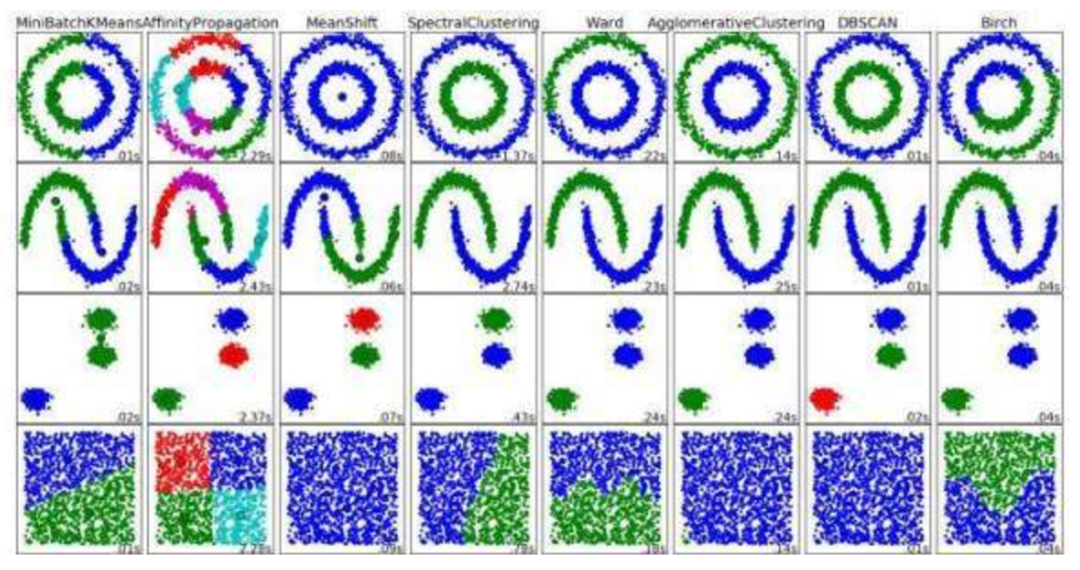
Scikit-learn 聚類算法
首先,閱讀這些介紹性文章; 第一個是 k 均值和 EM 聚類技術的快速比較,是對新聚類形式的一個很好的繼續,第二個是對 Scikit-learn 中可用的聚類技術的概述:
- 聚類技術比較:簡明技術概述,作者 Matthew Mayo。地址:http:// suo.im/4ctIvI
- 在玩具數據集中比較不同的聚類算法,Scikit-learn 文檔。地址:http:// suo.im/4uvbbM
期望最大化(EM)是概率聚類算法,並因此涉及確定實例屬於特定聚類的概率。EM 接近統計模型中參數的最大似然性或最大後驗估計(Han、Kamber 和 Pei)。EM 過程從一組參數開始迭代直到相對於 k 聚類的聚類最大化。
首先閱讀關於 EM 算法的教程。接下來,看看相關的 Scikit-learn 文檔。最後,按照教程使用 Python 自己實現 EM 聚類。
- 期望最大化(EM)算法教程,作者 Elena Sharova。地址:http:// suo.im/33ukYd
- 高斯混合模型,Scikit-learn 文檔。地址:http:// suo.im/20C2tZ。
- 使用 Python 構建高斯混合模型的快速介紹,作者 Tiago Ramalho。地址:http:// suo.im/4oxFsj
如果高斯混合模型初看起來令人困惑,那麼來自 Scikit-learn 文檔的這一相關部分應該可以減輕任何多餘的擔心:
高斯混合對象實現期望最大化(EM)算法以擬合高斯模型混合。
基於密度且具有噪聲的空間聚類應用(DBSCAN)通過將密集數據點分組在一起,並將低密度數據點指定為異常值來進行操作。
首先從 Scikit-learn 的文檔中閱讀並遵循 DBSCAN 的示例實現,然後按照簡明的教程學習:
- DBSCAN 聚類算法演示,Scikit-learn 文檔。地址:http:// suo.im/1l9tvX
- 基於密度的聚類算法(DBSCAN)和實現。地址:http:// suo.im/1LEoXC
第 4 步:更多的集成方法
上篇只涉及一個單一的集成方法:隨機森林(RF)。RF 作為一個頂級的分類器,在過去幾年中取得了巨大的成功,但它肯定不是唯一的集成分類器。我們將看看包裝、提升和投票。
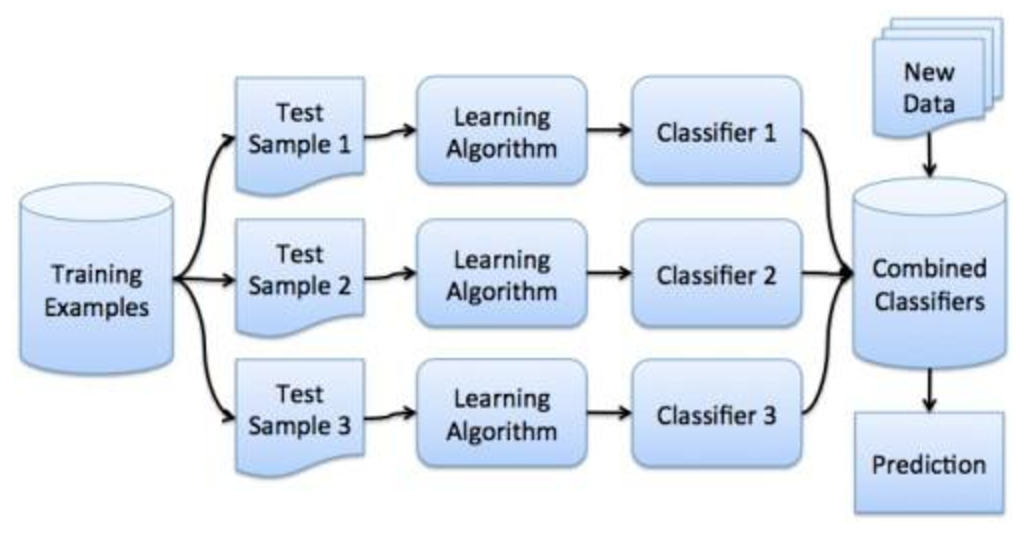
給我一個提升
首先,閱讀這些集成學習器的概述,第一個是通用性的;第二個是它們與 Scikit-learn 有關:
- 集成學習器介紹,作者 Matthew Mayo。地址:http:// suo.im/cLESw
- Scikit-learn 中的集成方法,Scikit-learn 文檔。地址:http:// suo.im/yFuY9
然後,在繼續使用新的集成方法之前,請通過一個新的教程快速學習隨機森林:
- Python 中的隨機森林,來自 Yhat。地址:http:// suo.im/2eujI
包裝、提升和投票都是不同形式的集成分類器,全部涉及建構多個模型; 然而,這些模型由什麼算法構建,模型使用的數據,以及結果如何最終組合起來,這些都會隨著方案而變化。
- 包裝:從同一分類算法構建多個模型,同時使用來自訓練集的不同(獨立)數據樣本——Scikit-learn 實現包裝分類器
- 提升:從同一分類算法構建多個模型,一個接一個地鏈接模型,以提高每個後續模型的學習——Scikit-learn 實現 AdaBoost
- 投票:構建來自不同分類算法的多個模型,並且使用標準來確定模型如何最好地組合——Scikit-learn 實現投票分類器
那麼,為什麼要組合模型?為了從一個特定角度處理這個問題,這裡是偏差-方差權衡的概述,具體涉及到提升,以下是 Scikit-learn 文檔:
- 單一評估器 vs 包裝:偏差-方差分解,Scikit-learn 文檔。地址:http:// suo.im/3izlRB
現在你已經閱讀了關於集成學習器的一些介紹性材料,並且對幾個特定的集成分類器有了基本了解,下面介紹如何從 Machine Learning Mastery 中使用 Scikit-learn 在 Python 中實現集成分類器:
- 使用 Scikit-learn 在 Python 中實現集成機器學習算法,作者 Jason Brownlee。地址:http:// suo.im/9WEAr
第 5 步:梯度提升
下一步我們繼續學習集成分類器,探討一個當代最流行的機器學習算法。梯度提升最近在機器學習中產生了顯著的影響,成為了 Kaggle 競賽中最受歡迎和成功的算法之一。
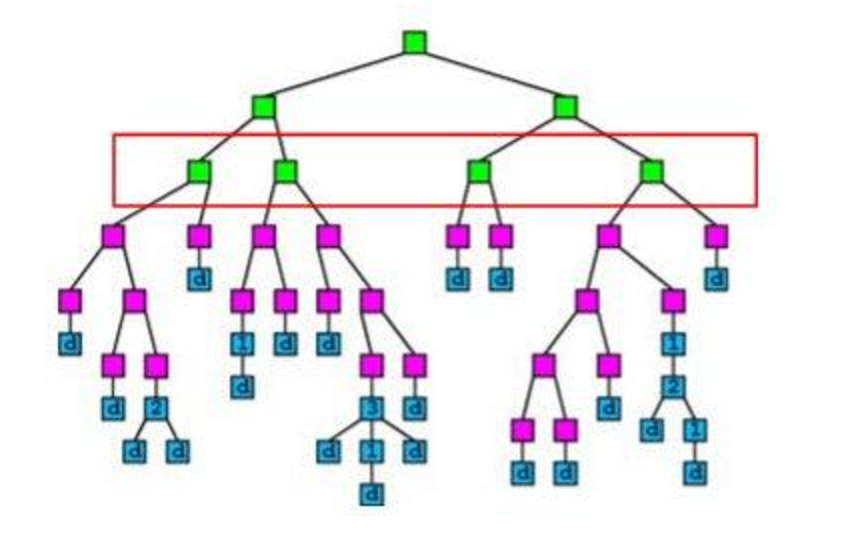
給我一個梯度提升 首先,閱讀梯度提升的概述:
維基百科條目:梯度提升。地址:http:// suo.im/TslWi
接下來,了解為什麼梯度提升是 Kaggle 競賽中「最制勝」的方法:
- 為什麼梯度提升完美解決了諸多 Kaggle 難題?Quora,地址:http:// suo.im/3rS6ZO
- Kaggle 大師解釋什麼是梯度提升,作者 Ben Gorman。地址:http:// suo.im/3nXlWR
雖然 Scikit-learn 有自己的梯度提昇實現,我們將稍作改變,使用 XGBoost 庫,我們提到過這是一個更快的實現。
以下鏈接提供了 XGBoost 庫的一些額外信息,以及梯度提升(出於必要):
- 維基百科條目:XGBoost。地址:http:// suo.im/2UlJ3V
- Ghub 上的 XGBoost 庫。地址:http:// suo.im/2JeQI8
- XGBoost 文檔。地址:http:// suo.im/QRRrm
現在,按照這個教程把所有匯聚起來:
- Python 中 XGBoost 梯度提升樹的實現指南,作者 Jesse Steinweg-Woods。地址:http:// suo.im/4FTqD5
你還可以按照這些更簡潔的示例進行強化:
- XGBoost 在 Kaggle 上的示例(Python)。地址:http:// suo.im/4F9A1J
- Iris 數據集和 XGBoost 簡單教程,作者 Ieva Zarina。地址:http:// suo.im/2Lyb1a
第 6 步:更多的降維
降維是通過使用過程來獲得一組主變量,將用於模型構建的變量從其初始數減少到一個減少數。
有兩種主要形式的降維:
1. 特徵選擇——選擇相關特徵的子集。地址:http:// suo.im/4wlkrj
2. 特徵提取——構建一個信息性和非冗餘的衍生值特徵集。地址:http:// suo.im/3Gf0Yw
下面是一對常用的特徵提取方法。
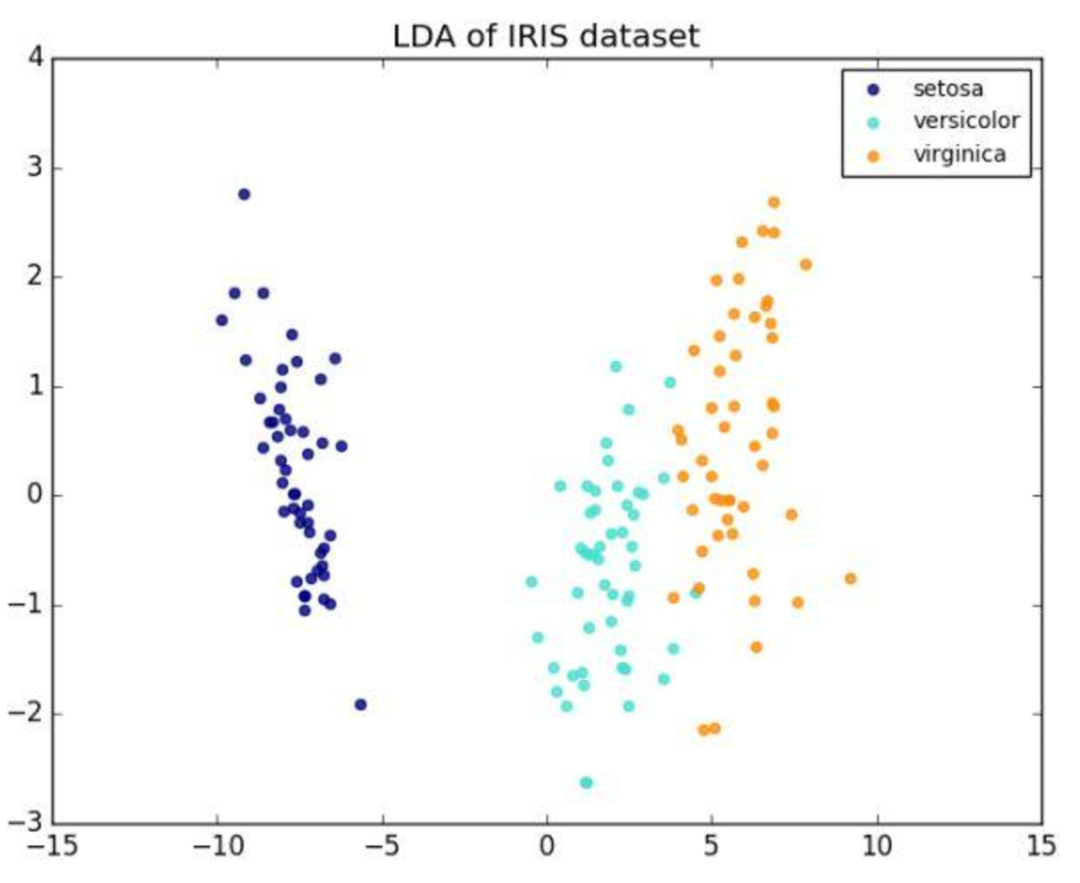
主成分分析(PCA)是一種統計步驟,它使用正交變換將可能相關變量的一組觀測值轉換為一組稱為主成分的線性不相關變量值。主成分的數量小於或等於原始變量的數量。這種變換以這樣的方式定義,即第一主成分具有最大可能的方差(即考慮數據中盡可能多的變率)
以上定義來自 PCA 維基百科條目,如果感興趣可進一步閱讀。但是,下面的概述/教程非常徹底:
- 主成分分析:3 個簡單的步驟,作者 Sebastian Raschka。地址:http:// suo.im/1ahFdW
線性判別分析(LDA)是 Fisher 線性判別的泛化,是統計學、模式識別和機器學習中使用的一種方法,用於發現線性組合特徵或分離兩個或多個類別的對像或事件的特徵。所得到的組合可以用作線性分類器,或者更常見地,用作後續分類之前的降維。
LDA 與方差分析(ANOVA)和回歸分析密切相關,它同樣嘗試將一個因變量表示為其他特徵或測量的線性組合。然而,ANOVA 使用分類獨立變量和連續因變量,而判別分析具有連續的獨立變量和分類依賴變量(即類標籤)。
上面的定義也來自維基百科。下面是完整的閱讀:
- 線性判別分析——直至比特,作者 Sebastian Raschka。地址:http:// suo.im/gyDOb
你對 PCA 和 LDA 對於降維的實際差異是否感到困惑?Sebastian Raschka 做瞭如下澄清:
線性判別分析(LDA)和主成分分析(PCA)都是通常用於降維的線性轉換技術。PCA 可以被描述為「無監督」算法,因為它「忽略」類標籤,並且其目標是找到使數據集中的方差最大化的方向(所謂的主成分)。與 PCA 相反,LDA 是「監督的」並且計算表示使多個類之間的間隔最大化的軸的方向(「線性判別式」)。
有關這方面的簡要說明,請閱讀以下內容: LDA 和 PCA 之間的降維有什麼區別?作者 Sebastian Raschka。地址:http:// suo.im/2IPt0U
第 7 步:更多的深度學習
上篇中提供了一個學習神經網絡和深度學習的入口。如果你的學習到目前比較順利並希望鞏固對神經網絡的理解,並練習實現幾個常見的神經網絡模型,那麼請繼續往下看。
首先,看一些深度學習基礎材料:
- 深度學習關鍵術語及解釋,作者 Matthew Mayo
- 理解深度學習的 7 個步驟,作者 Matthew Mayo。地址:http:// suo.im/3QmEfV
接下來,在 Google 的機器智能開源軟件庫 TensorFlow(一個有效的深度學習框架和現今幾乎是最好的神經網絡工具)嘗試一些簡明的概述/教程:
- 機器學習敲門磚:任何人都能看懂的 TensorFlow 介紹 (第 1、2 部分)
- 入門級解讀:小白也能看懂的 TensorFlow 介紹 (第 3、4 部分)
最後,直接從 TensorFlow 網站試用這些教程,它實現了一些最流行和常見的神經網絡模型:
- 循環神經網絡,谷歌 TensorFlow 教程。地址:http:// suo.im/2gtkze
- 卷積神經網絡,谷歌 TensorFlow 教程。地址:http:// suo.im/g8Lbg
此外,目前一篇關於 7 個步驟掌握深度學習的文章正在寫作之中,重點介紹使用位於 TensorFlow 頂部的高級 API,以增模型實現的容易性和靈活性。我也將在完成後在這兒添加一個鏈接。
相關的:
進入機器學習行業之前應該閱讀的 5 本電子書。地址:http:// suo.im/SlZKt
理解深度學習的 7 個步驟。地址:http:// suo.im/3QmEfV
機器學習關鍵術語及解釋。地址:http:// suo.im/2URQGm
(本文經 地球的外星人君 授權轉載,並同意 TechOrange 編寫導讀與修訂標題,原文標題為 〈 只需十四步:從零開始掌握 Python 機器學習(附資源)〉。)
【TechOrange 徵才:社群編輯+實習編輯】 你是否常在各類豐富的科技趨勢裡流連忘返? 你是否常被創業故事弄得熱血沸騰無法成眠? 我想你大概就是得了 TO 病,不加入不行了。 準備好你的履歷自傳,寄至 jobs@fusionmedium.com 記得標註你要「應徵 TO 社群編輯」,才不會跑錯棚哦! >> 詳細職缺訊息
延伸閱讀
附範例與完整程式碼!手把手帶著你用 Python 做出爬蟲、抓取網頁資料 2017 年 15 個最好用 Python 庫,學習資料科學、機器學習絕對不容錯過 【不是工程師,也可以作文本分析】用 R 與 Python 語言,七步驟解決文本挖掘的一切痛苦
2016 前 20 大 Python 機器學習開源項目:排行榜大刷新,Scikit-learn 穩坐龍頭寶座